原文:https://mp.weixin.qq.com/s/arzvLZIQg65sOjUahdmGVg
之前写过利用jmeter做分布式压测的简略介绍,当时只是介绍了背景和原因,以及基本的配置操作,有同学说写得不够详细。正好今年双十一,我司的全链路压测,也尝试了jmeter分布式压测的手段。这篇文章,介绍下利用jmeter在NGUI模式下进行分布式压测的一些小技巧和注意事项。
一、压测机
1、数量&成本
无论是从成本角度还是维护的难易方面,压测机的数量,适量就好。举个例子,8C16G的一台服务器,部署jmeter后,根据我个人的测试比对数据,配置≤1500个线程数,最好。太多了性能损耗较大,延时高;太少了又浪费。
2、controller&agent
模拟的并发线程数超过5K,我个人建议留出一台做专门的controller机器,主要是避免agent机器数据上报带来的影响(如果有其他的数据存储+可视化服务,可以忽略)。
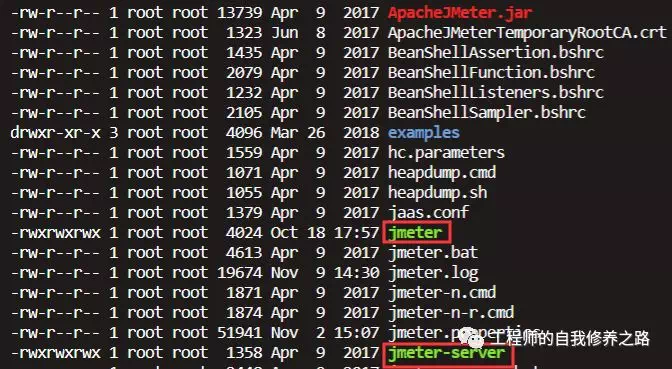
3、服务授权
如果压测启动和服务配置都是root权限,那么在linux环境下,需要给jmeter和jmeter-server授权,命令为 chmod 777 jmeter ,授权后,显示如下:
二、服务通信
1、网络
所有的压测机和被测服务,最好在同一个网段内,尽可能减少时延问题(如果不在同一个网段,就需要找运维建立专门的网络通道,这个很浪费)。
2、端口
在分布式压测配置时,需要在controller机器的jmeter.properties文件中配置agent机器的IP+端口,默认端口1099,如果该端口没有被占用,则无需配置端口信息,比如:

3、内网和公网
如果压测机在内网,而访问的请求地址(现在都是统一的网关域名)在外网,就要注意一点:内网到公网一般是有带宽限制的,最好在压测开始前和运维确认。
三、数据切割
压测时候需要用到参数化数据,有些业务场景是需要先登录再进行操作的,或者某些数据具有唯一属性。在分布式压测时候,需要注意,进行均匀的数据切割,确保每个请求的入参请求都是唯一的(可共用的参数不用切割)。其实,在参数化数据准备阶段,就应该考虑到这个问题,数据的可用性、唯一性以及数量级。
四、服务启动
压测机到位,服务授权配置好了,脚本也写好了,网络也没问题,那么如何在NGUI模式(即linux环境)下启动呢?
1、以服务形式启动agent机
网上很多其他博客都写着利用命令 ./jmeter-server 启动压测服务,但这样有个缺点,只要服务连接中断,这个压测服务就不可用了。
但是以后台服务的形式启动agent机器的jemter-server,就不用担心服务不可用的问题,命令为 nohup sh jmeter-server & ,示意如下:

PS:注意,输入如上命令后,需要回车两次,然后通过命令,即可查看服务是否启动成功。
2、压测启动的2种方式
①、指定压测机启动,命令: ./jmeter -n -t /path/test.jmx -R 127.0.0.1,127.0.0.2
②、启动所有压测机,命令: ./jmeter -n -t /path/test.jmx -r ,示意如下:

3、更多命令
Apache-Jmeter-用户手册:命令行选项列表:https://jmeter.apache.org/usermanual/get-started.html#override
